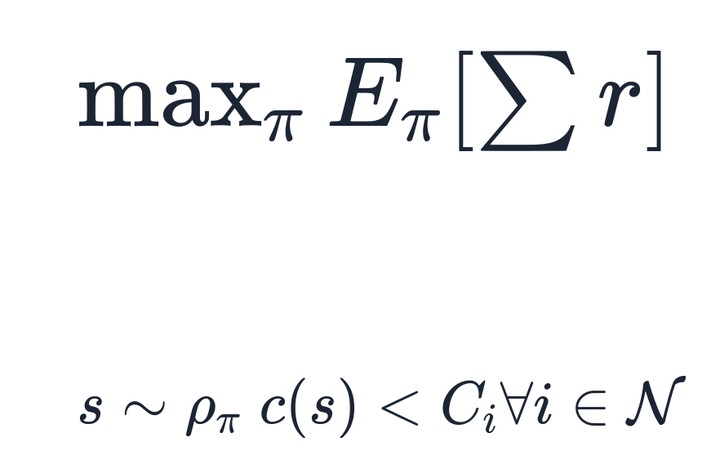 Constraint Optimization
Constraint Optimization
Reinforcement Learning is a tool which helps an artificial agent to “Learn by Doing”. The agents interact with the system and learn the ropes becoming better in each iteration. Most of RL research focusses on training agents in simulations as during early iterations of learning some of the agent’s actions may be harmful to itself or the user or its surroundings. But many-a-times it’s not possible to train in simulation owing to either difficulty in the representation of the environment virtually or due to the sheer gap in generalization performance. Hence, in such cases, Safe-Reinforcement learning algorithms help train the agents considering the system constraints.
There are several ways to enforce AI Saftey. In this work, we have selected two aspects of safety, Performance Bonds and Constraint Optimization.
One aspect of AI-Saftey could be described in terms of algorithmic performance, i.e. the actions of an agent are considered safe until the overall performance lies above a certain threshold. Using techniques like Importance Sampling one can estimate the agent’s policy performance before it is executed.
The other way to enforce safety is by making sure the algorithm makes updates which satisfy certain constraints. The vast literature on constraint optimization boasts several techniques which ensure that the policy transitions only from one safe state into the next. For these methods, one needs to set up functional forms for each of the constraints.
We see that these techniques ameliorate the issues with safety-aware training.
Sohan Rudra
Graduate Student at the Department of Mathematics
My research interests include Reinforcement Learning, Computer Vision, Robotics and Computational Mathematics.